Machine Intelligence Can't Infer What the Catalog Didn't Record
Conversational search, agentic checkout, and personalized recommendation share the same architectural dependency: product data structured for machine interpretation. Most fashion catalogs were built for human browsing, and the gap between those two design objectives is where AI commerce roadmaps keep stalling.
Admiral Neritus Vale
Every AI commerce capability this publication has covered — conversational search, agentic checkout, personalized recommendation — depends at its foundation on product data structured for machine interpretation. Fashion’s taxonomy systems were not built for that. They were built for human browsing, and the gap between those two design objectives is where AI roadmaps keep stalling.
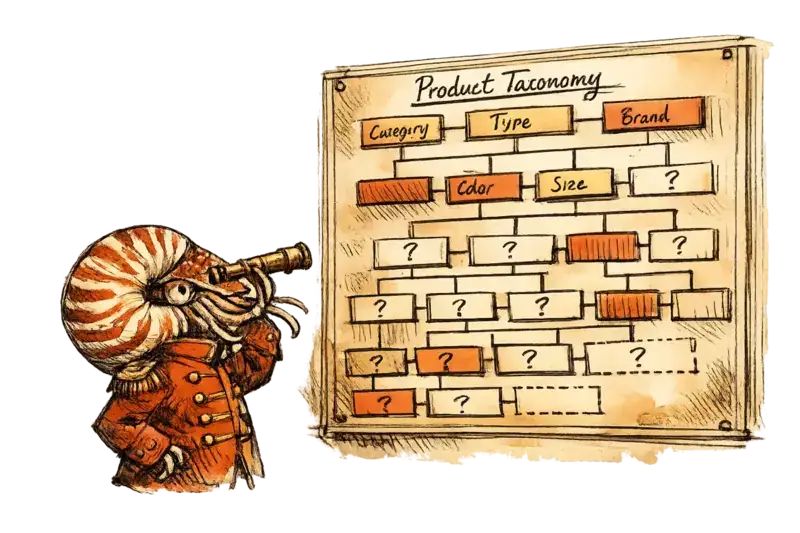
A 2021 piece in FashionUnited, authored by auto-tagging vendor Pixyle.ai, frames the taxonomy problem accurately before it frames the solution: product taxonomy is “a well defined data structure of fashion categories and attributes which is supporting the method of categorizing, organizing, and systematically classifying items.” That definition is right. The implication the industry has underweighted is that categorizing for shoppers and categorizing for machines demand different attribute schemas, different granularity, and different consistency standards.
Fashion taxonomy was designed around what human buyers could interpret when filtering a website. A shopper reads “vintage-inspired,” “perfect for weddings,” and “runs small” and applies cultural inference to fill gaps the text leaves open. A recommendation engine has no such reserves — it needs structured fields: occasion code, silhouette classification, fit variance expressed as measurement data, fabric composition by percentage. When those fields are missing, inconsistent, or encoded in freeform prose, the machine either guesses or aggregates across conflicting signals. The output is technically plausible and commercially wrong. As we reported on March 27, citing ChannelEngine, in our analysis of AI search visibility, incomplete attributes make products harder to surface in AI-driven environments because AI agents rely on structured product data rather than browsing pages as a human would. Every AI capability downstream of discovery has the same dependency.
The auto-tagging response and its limits
The industry’s primary response has been automated attribute tagging. Vendors including Pixyle.ai and YesPlz have built computer vision pipelines that extract product attributes from images — neckline, sleeve length, pattern, color — without manual entry. A YesPlz case study puts the efficiency case concretely: manually tagging 2,000 fashion products requires at least 10 days of human labor and roughly $1,600 at $20/hour — a rate YesPlz applies to the California market, higher than the general California minimum wage at the time of original publication; automated tagging completes the same work in hours for $200–$600 (per a YesPlz case study of two small Shopify retailers). That is a real operational improvement, and it addresses a genuine production bottleneck.
What it does not solve is the schema problem.
If a retailer’s taxonomy has no fields for occasion category, fit intent, or care compatibility, image-processing pipelines cannot fill them — because there is nothing to fill. The schema being enriched was designed around what human merchandisers understood when they set up filters for “casual” or “wedding guest” more than a decade ago. Those are browsing heuristics. A conversational AI asked to surface a dry-clean-only silk blouse for a summer cocktail party needs discrete fields for occasion, fabric type, and care instruction. Many catalogs either omit those fields or handle them inconsistently across product types and buying seasons. The absence is invisible until an AI system tries to reason across the catalog at scale.
What vision inference gets right — and where it stops
The standard counter-argument is that modern vision models can infer attributes from images without structured fields. That is partially correct and importantly bounded. Vision inference performs well on attributes with visible surface characteristics: color, pattern, silhouette, sleeve length. It degrades on non-visual attributes that drive purchase decisions — occasion appropriateness, warmth rating, size consistency across colorways. It also generates inconsistent outputs when the same product is photographed at different angles or catalogued across colorways in different seasons.
FashionUnited’s 2024 survey of AI across the fashion value chain notes that systems like Heuritech distinguish “over 2,000 different fashion details” from social imagery — a genuine technical achievement. But trend detection and retail recommendation reasoning are different tasks. Trend detection aggregates signals across millions of images to surface emerging patterns. Recommendation reasoning requires consistent, per-product structured attributes that probabilistic inference cannot supply at uniform quality across a full catalog.
Fashion’s specific exposure
Fashion has greater exposure to this problem than most categories. A laptop can be described accurately with processor, storage, weight, and screen size — all measurable, largely objective. A black women’s ponte blazer requires silhouette, fabrication, fit type, occasion range, size variance, and seasonal positioning to be genuinely recommendable across the contexts where purchase intent fires. The ambiguity doesn’t reduce when AI enters the pipeline; it compounds. Conversational search surfaces plausible results that miss intent. Agentic checkout purchases a product that matches the query but not the wardrobe; recommendation engines push the right category to the wrong occasion.
The retailers with a structural advantage in the next AI commerce cycle are not the ones running the most sophisticated algorithm over a thin data layer. They are the ones whose product data is already structured to support inference rather than browsing — the ones who asked what a machine needs to reason about a product before asking what the AI feature roadmap requires. Fixing the taxonomy schema — extending fields, enforcing consistency standards, auditing what machines need rather than what human merchandisers remember to complete — is unglamorous infrastructure work. The capabilities it unlocks are not.